The Four Horsemen of Production AI: From Prototype to Profit
Your AI prototype works, but will it survive in the real world? Uncover the four silent killers of AI projects: Cost, Latency, Reliability, and Specialization and learn the architecture to conquer them.
You’ve done it. You built an AI agent using GPT-5 or Claude 4, and it works perfectly. It analyzes data, calls functions, and handles complex user requests with stunning accuracy. The demo is a massive success, and everyone is excited to roll it out.
And then you launch.
Suddenly, the magic starts to fade. Users complain the app is slow. The finance department calls about a skyrocketing API bill. The system occasionally outputs strange, unusable responses that crash your backend.
Welcome to the harsh reality of production AI. The leap from a working prototype to a scalable, reliable system is a chasm, and crossing it means facing the Four Horsemen of Production AI: Cost, Latency, Reliability, and Specialization.
While SOTA (State-of-the-Art) models are brilliant generalist thinkers, relying on them exclusively for high-volume tasks is a recipe for failure. Let's break down why.
The Seductive Power of the SOTA Generalist
First, let's give credit where it's due. Models like OpenAI's GPT-5, Anthropic's Claude 4 Opus, and Google's Gemini 2.5 Pro are technological miracles. Their ability to perform complex reasoning from a simple prompt is what sparked this revolution.
With features like Tool Calling and Forced JSON Mode, you can ask the model to analyze a user's request and respond with a perfectly formatted JSON object to call a function in your code. For a developer, this feels like a superpower. You can build a complex agent in a few hours that would have taken a team of engineers months to build before.
This is perfect for a demo. It's perfect for a low-volume internal tool. But when you open the floodgates to real users, the Horsemen arrive.
The First Horseman: Cost (The Great Filter)
The most brutal and least forgiving horseman is Cost. SOTA models are incredibly expensive to run, and what seems like pennies in testing becomes a financial disaster at scale.
Let's imagine a simple agent that triages 100,000 support emails per day. Each email analysis requires about 1,500 tokens (including the prompt and the email content).
Here’s the painful math:
| Model / Approach | Cost per 1M Input Tokens | Daily Cost | Monthly Cost (30 days) |
|---|---|---|---|
| Claude 4 Opus | $15.00 | (100,000 emails * 1,500 tokens/email / 1M) * $15 = $2,250 | $67,500 |
| GPT-5 Turbo | $10.00 | (100,000 emails * 1,500 tokens/email / 1M) * $10 = $1,500 | $45,000 |
| Fine-Tuned Specialist (e.g., Gemma 3 270M) | $0 (API cost) | Cost of a dedicated GPU server ≈ $20 | ~$600 |
The difference is staggering. The SOTA approach is 50-100x more expensive. You are paying a massive premium for a model that knows about astrophysics and Shakespearean literature just to decide if an email is spam.
At scale, cost is the great filter. Repetitive, high-volume tasks are economically unviable on premium SOTA models.
The Second Horseman: Latency (The Speed of Light is a Hard Limit)
Your users expect a snappy, responsive application. An AI agent powered by a SOTA API call is fundamentally incapable of delivering that.
-
The SOTA API Call: Your request travels from your server, across the internet to the provider's data center, waits in a queue, gets processed by a massive distributed model, and the result travels all the way back.
- Typical Time: 800ms - 5,000ms
-
The Local Specialist Model Call: Your application calls a fine-tuned model running on a GPU in the same data center (or even the same machine).
- Typical Time: 20ms - 100ms
A 2-second delay might be acceptable for a one-off report, but it's a death sentence for a real-time chatbot, an interactive tool, or any agent that needs to make several decisions in a sequence.
For user-facing or real-time applications, network and model latency is a deal-breaker.
The Third Horseman: Reliability (The 99.999% Imperative)
Modern SOTA models are very reliable at producing the format you request (e.g., JSON). But that's not the same as logical reliability.
A SOTA model is a generalist. It hasn't been exclusively trained on your business's specific edge cases. It might correctly output {"action": "reply"} but for the wrong reason, or misinterpret a subtle but critical piece of your business logic.
A fine-tuned specialist, on the other hand, has been trained on thousands of your specific examples. It has learned the nuances, the exceptions, and the unwritten rules of your domain. It becomes a robotic, predictable component.
Production systems demand near-perfect logical predictability. This is achieved by training on domain-specific data, not just clever prompting.
The Fourth Horseman: Specialization (Your Data is Your Moat)
Your biggest competitive advantage is your private data and proprietary business logic. A SOTA model knows nothing about this. You can try to feed it context with every API call (a technique called Retrieval-Augmented Generation, or RAG), but this has serious drawbacks:
- It dramatically increases the prompt size, driving up Cost and Latency.
- It requires sending your sensitive, proprietary data to a third-party API, creating a security risk.
Fine-tuning bakes this knowledge directly into the model's weights. You create a true expert that speaks your company's internal language and operates securely within your own infrastructure.
A fine-tuned model turns your private data from a context window liability into a baked-in competitive advantage.
The Solution: The Hybrid "Mixture of Experts" Architecture
The answer is not to abandon powerful SOTA models. The answer is to use them correctly. The dominant architecture for production AI is a hybrid system that uses the right tool for the right job.
-
The Orchestrator (SOTA Model): Use a model like GPT-5 or Claude 4 for what it does best: complex, low-volume, high-level reasoning. It acts as the "brain" of the operation.
- Example: A user gives a complex command: "Analyze our Q3 sales data, find the top 3 underperforming regions, and draft an email to each regional manager outlining a performance plan." This is a perfect job for a SOTA model.
-
The Workers (Fine-Tuned Specialists): The Orchestrator's plan involves delegating high-volume tasks to an army of cheap, fast, and reliable specialists.
- Example: To fulfill the request, the Orchestrator might call a fine-tuned "Sentiment Analysis" agent 50,000 times on customer feedback, then call a "Data Query" agent to pull sales figures, and finally a "Drafting" agent trained on your company's communication style.
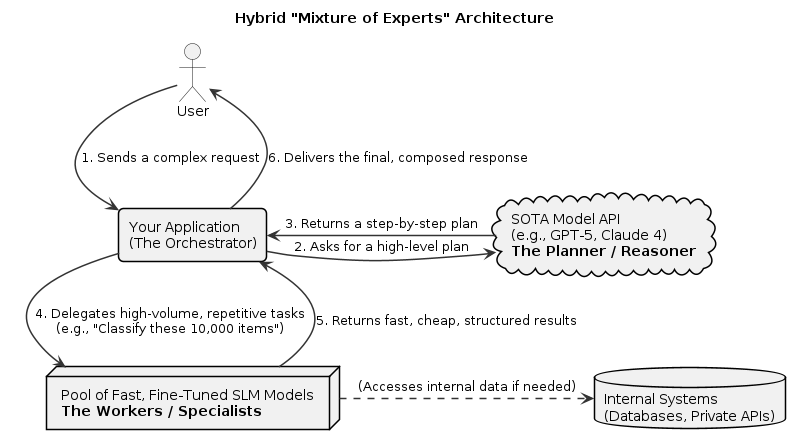
This architecture gives you the best of both worlds: the brilliant reasoning of a generalist and the speed, efficiency, and reliability of a specialist.
Moving from prototype to production isn't about finding the one "best" model. It's about evolving from a single brain into a sophisticated, multi-part system. Don't let the Four Horsemen end your project; master them by building a resilient system of specialized agents.