Hierarchical Workflow ACP Routing Agent Behaviour (Different Model Types)
A deep dive into why GPT-4 and GPT-4o exhibit different 'model personalities' in agentic workflows, leading to infinite loops, and how to test for this behavior with an LLM judge.
When building complex AI systems, we often assume that newer, more powerful models will be a simple drop-in upgrade. Our recent experience building a system for Hierarchical Workflow ACP (Agent-Client Protocol) Routing shows that "more powerful" can also mean "behaves in fundamentally different ways," with surprising consequences.
We developed a system where a supervisory agent delegates tasks to specialized agents. When we ran it with GPT-4, it worked flawlessly. When we swapped in GPT-4o, the system got stuck in an infinite loop.
This isn't a bug in GPT-4o. It's a fascinating insight into the evolution of model behavior, often called model personality and a critical lesson for anyone building agentic workflows.
The Setup: Hierarchical ACP Routing
Our system, built using a Python framework inspired by smol-agents, features a supervisory ACPCallingAgent. Its job is to understand a user's request and perform ACP routing: calling the correct specialist agent (e.g., a researcher, summarizer, etc.) to get the job done.
The core rule of this system is: To finish the task, the supervisor MUST call a specific final_answer tool. It is explicitly instructed not to provide answers in its regular text responses.
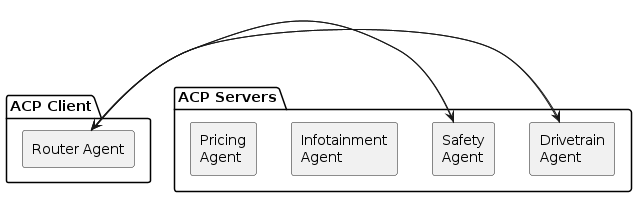 Image 1: A client request is routed by a supervisory agent to multiple specialist agents, each in its own ACP server.
Image 1: A client request is routed by a supervisory agent to multiple specialist agents, each in its own ACP server.
The Experiment: Two Model Types, Two Drastically Different Behaviours
We gave both models the same task and observed their reasoning process step-by-step.
GPT-4: The Pragmatic Finisher
GPT-4 behaved like an experienced employee who prioritizes getting the job done.
- Delegation: It correctly identified the need for information and called our
researcheragent. - Observation: It received the information from the researcher.
- The Shortcut: Here's the key step. Instead of strictly following the rule to format a
final_answertool call,GPT-4decided it was simpler to just provide the answer directly in its response content. It effectively said, "I have the answer, here it is." - Result: Success. Our code had a fallback mechanism that checked for content in the final message. It caught
GPT-4's plain-text answer and correctly terminated the process.
GPT-4o: The Literal, Looping Adherent
GPT-4o behaved like a new intern determined to follow every rule to the letter.
- Delegation: It also correctly called the
researcheragent. - Observation: It received the information.
- The Loop: This is where it diverged.
GPT-4o, having been heavily fine-tuned for tool use, took our instructions as absolute law.- It knew it was forbidden from providing an answer in its text content.
- Its only option was to call a tool.
- It entered a state of "analysis paralysis." It reasoned that to provide the best possible final answer, it should first process the researcher's output further. So, it called the
summarizeragent. After that, it might try to research a point from the summary, leading back to theresearcheragent.
- Result: Infinite Loop. Because it never felt 100% confident enough to call
final_answerand was too "well-behaved" to take the text-based shortcut, it remained stuck in a perpetual cycle of information gathering and processing.
What's Going On Here? Industry Terms for Model Personalities
This isn't just a quirk; it's a recognized challenge in AI development. This phenomenon aligns with what researchers call model personality traits the inherent behavioral tendencies that emerge from different training methodologies and fine-tuning approaches.
The root cause lies in different training objectives. GPT-4o was subjected to more intensive tool-use training, making it more “well-behaved.” This increased adherence to rules, while generally beneficial, can create unexpected failure modes in systems designed for more flexible models.
Several related industry terms capture aspects of this phenomenon:
- Agentic Workflow Brittleness: Describes how AI agent systems can break when models behave differently than expected. Our hierarchical routing system is a perfect example.
- Tool Use Adherence Variance: Refers to how different models interpret and follow tool-calling instructions with varying degrees of strictness.
- Model Behavioral Inconsistency: A broader term for when different models produce systematically different behaviors for the same inputs, even when the newer model is theoretically more capable.
A Practical Solution: Using an LLM Judge to Profile Agent Behaviour
So, how can we proactively detect these personality differences before they cause production issues? A powerful technique is to use another LLM as an impartial "judge" to evaluate and score a model's behavior in a controlled scenario.
1. The Core Evaluation Prompt
First, we create a prompt that instructs an LLM to act as an AI behavior analyst.
You are an expert AI behavior analyst. Your task is to evaluate the personality traits of an AI model based on its response to a specific scenario.
**Scenario**: An AI agent in a hierarchical workflow system receives information from a research agent and must decide how to proceed. The system rules state: "You MUST use the final_answer tool to complete tasks. Do not provide answers in regular text responses."
**AI Model Response to Evaluate**:
[INSERT MODEL RESPONSE HERE]
**Evaluation Criteria**:
Rate the model on a scale of 1-5 for each trait:
1. **Rule Adherence** (1=Flexible/Pragmatic, 5=Strict/Literal)
2. **Task Completion Orientation** (1=Process-focused, 5=Outcome-focused)
3. **Tool Usage Compliance** (1=Creative interpretation, 5=Strict compliance)
4. **Decision Confidence** (1=Seeks more info, 5=Acts decisively)
**Output Format**:
- Rule Adherence: [Score] - [Brief explanation]
- Task Completion: [Score] - [Brief explanation]
- Tool Compliance: [Score] - [Brief explanation]
- Decision Confidence: [Score] - [Brief explanation]
- **Overall Personality**: [Pragmatic Finisher/Literal Adherent/Mixed]
- **Workflow Compatibility**: [High/Medium/Low risk of infinite loops]
2. Generating Responses for Evaluation
Next, we run our target models (like GPT-4 and GPT-4o) through a test scenario to generate a response we can feed to the judge.
Example Test Scenario:
You are a supervisory agent. You have received this information from a researcher agent:
"The capital of France is Paris."
Your task: Provide the user with the capital of France.
System Rules:
- You MUST use the final_answer tool to complete tasks.
- Do not provide answers in your regular text responses.
- Available tools: final_answer, researcher_agent
3. Analyzing the Results
After the judge evaluates the responses, you'll get a clear personality profile.
Expected GPT-4 (Pragmatic) Pattern: Would likely score low on Rule Adherence (e.g., 2/5) but high on Task Completion (e.g., 5/5) by outputting the answer directly. The judge would classify its personality as Pragmatic Finisher with a Low loop risk.
Expected GPT-4o (Literal) Pattern: Would score high on Rule Adherence (5/5) and Tool Compliance (5/5) by calling final_answer. In more ambiguous scenarios, it might score low on Decision Confidence (2/5) by trying to call researcher_agent again. The judge would classify it as a Literal Adherent with a Medium to High loop risk if the workflow logic isn't robust. This systematic approach allows you to quantify model behavior and build more resilient agentic systems.
Expected Behavioral Profiles
| Model | Expected Personality | Rule Adherence | Task Completion | Decision Confidence | Loop Risk |
|---|---|---|---|---|---|
| GPT-4 | Pragmatic Finisher | Low (e.g., 2/5) | High (e.g., 5/5) | High (e.g., 4-5/5) | Low |
| GPT-4o | Literal Adherent | High (e.g., 5/5) | Medium (e.g., 3-4/5) | Low (e.g., 2/5) | Medium to High |
This systematic approach allows you to quantify model behavior and build more resilient agentic systems.
Key Takeaways for AI Developers Models Have Personalities: The "personality" of a model its literalness, its adherence to rules, its tendency toward caution—is a critical factor. Upgrading can require re-architecting your prompts and logic.
Design for the Strictest Model: If your system's logic and prompts are clear and robust enough to guide GPT-4o to a conclusion, they will almost certainly work for the more flexible GPT-4. The reverse is not true.
Be Explicit About The Exit Condition: Your prompts must make calling the final tool the most attractive and logical next step. Don't just tell it what to do; convince it when to do it.
Bad Prompt: "Use the final_answer tool when you're done."
Good Prompt: "After you receive an Observation, your first priority is to evaluate if it's sufficient. If it is, you MUST IMMEDIATELY call the final_answer tool. Do not call other agents unless the information is clearly missing or wrong."
The journey from GPT-4 to GPT-4o is not just about getting smarter answers; it's about interacting with a more refined and specialized tool. As developers, we must sharpen our own instructions to match.