Choosing the Right LLM Implementation for Classification Tasks
Comparing different approaches to implement LLM-based classifiers: analyzing trade-offs between quantized fine-tuned models, RAG systems with frontier/quantized models, and direct prompting.
When implementing LLM-based classification systems, architects must choose between 7 main approaches:
Implementations Overview
| Implementation | Description | Resource Usage | Latency | Accuracy | Best For | Not Recommended For |
|---|---|---|---|---|---|---|
| Quantized Fine-Tuned | Specialized model trained for specific task | Low | < 100ms | High | High query volume, Fast responses, Low cost per inference | Frequent updates, Complex edge cases |
| Frontier Fine-Tuned | Fine-tuned GPT-4/Claude model | Very High | 500ms-1s | Very High | Maximum accuracy, Enterprise budget, Complex classifications | Cost constraints, High volume needs |
| RAG + Frontier Model | Vector DB + Latest LLM | High | 1-2s | Very High | Dynamic knowledge base, High accuracy, Complex reasoning | Strict latency, Budget constraints |
| RAG + Quantized | Vector DB + Compressed LLM | Medium | 500ms-1s | Medium | Balance of speed/cost, Regular updates, Medium scale | Very high accuracy, Simple fixed patterns |
| Instruct Frontier | Direct prompting of latest LLM | High | 1-2s | High | Low volume needs, Varied use cases, Quick deployment | High volume, Strict consistency |
| *Hybrid Fine-tuned | Multiple specialized models with voting | High | 200-300ms | Very High | Mixed complexity tasks, High accuracy, Moderate scale | Simple classifications, Budget constraints |
| *Hybrid Instruct | Multiple frontier models with voting | Very High | 2-3s | Very High | Maximum accuracy, Complex varied tasks, Enterprise scale | Cost sensitivity, Speed requirements |
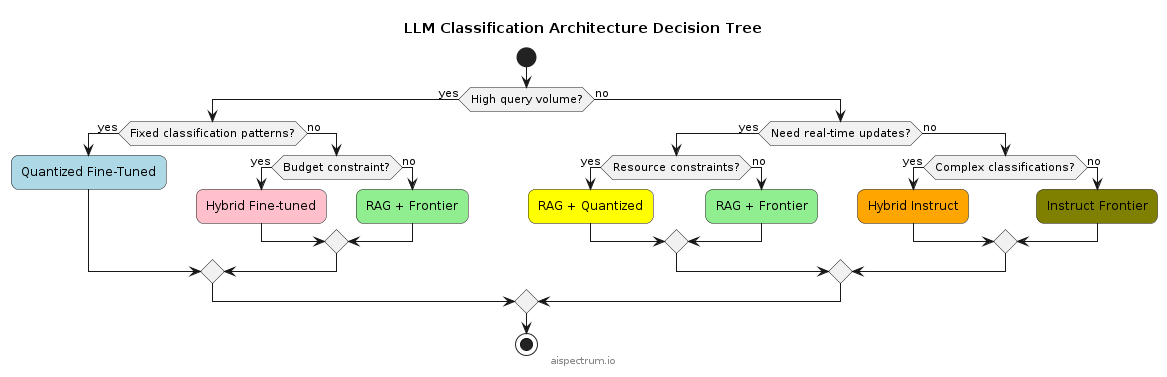
Real World Applications
Job Classification
-
Implementation: Quantized Fine-Tuned
-
Scale: Millions daily
-
Dataset Sample:
Job Zone,Code,Title 4,13-2011.00,Accountants 2,27-2011.00,Actors 4,15-2011.00,Actuaries
- Why: Fixed categories, instant response needed
Legal Docs Analysis
-
Implementation: RAG + Frontier
-
Scale: Thousands daily
-
Dataset Sample:
type: contract clauses: [liability, term] jurisdiction: CA
- Why: Complex reasoning needed
Product Categorization
-
Implementation: RAG + Quantized
-
Scale: 100k daily
-
Dataset Sample:
title: Nike Air Max dept: Footwear category: Athletic
- Why: Balance speed/accuracy
Academic Papers
-
Implementation: Instruct Frontier
-
Scale: 1k daily
-
Dataset Sample:
title: ML Advances keywords: AI, Neural journal: Nature
- Why: Complex categorization
Real-World Example
Consider an O*NET job code classifier:
# Example: Quantized Fine-Tuned Approach
response = model.predict("What is the O*NET code for: Economists")
# Returns: 19-3011.00 in <100ms