Why Is My LLM Getting Dumber? (Cost-Cutting Reality)
Analysis of how Large Language Models like ChatGPT are being optimized for cost efficiency, sometimes at the expense of intelligence, through techniques like pruning and quantization.
Recent benchmarks show a noticeable decline in LLM performance, particularly with ChatGPT's default model (GPT-4o). Let's analyze the technical reasons behind these changes.
(Some) LLM providers like OpenAI are implementing optimization strategies that favor response speed and cost efficiency over technical precision. This shift particularly affects complex reasoning and specialized knowledge tasks.
Techniques
Here's what's happening at the technical level:
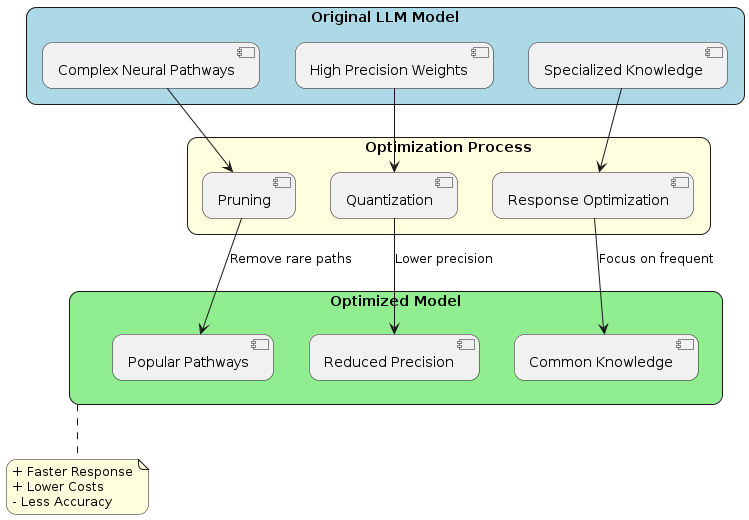
| Technique | Implementation | Impact |
|---|---|---|
| Pruning | Removes less-activated neural pathways | Reduced model complexity and specialized knowledge |
| Quantization | Decreases numerical precision in weights | Smaller memory footprint, lower computational cost |
| Response Optimization | Prioritizes frequently used patterns | Better performance on common queries, reduced accuracy on edge cases |
Why These Changes?
The economics of running large-scale LLM infrastructure:
- 💰 Computational costs at scale
- 🌍 Growing user base and request volume
- ⚡ Infrastructure optimization requirements
The Trade-offs
Optimizations
- Improved response latency
- Reduced operational costs
- Enhanced performance on common queries
Compromises
- Decreased accuracy on technical tasks
- Reduced reasoning depth
- Lower performance on standardized benchmarks
Development Considerations
For technical implementations:
- Use specialized models for complex tasks
- Implement robust validation for critical operations
- Consider model-specific limitations in your architecture
- Evaluate cost-performance trade-offs
Current Model Landscape 🧠
Recent benchmarks show significant changes in model performance:
- See the Top 10 performing Models at AI Spectrum
- Default ChatGPT has dropped from top 10 in performance rankings
- Consider alternatives like Claude-3.5-sonnet or Grok2 for advanced/complex tasks
The Bottom Line
These optimizations reflect the reality of scaling AI infrastructure. While general-purpose queries remain effective, developers should carefully consider model selection for specialized applications.
Remember: Model selection should align with your specific use case requirements and performance needs.