LLM Agents Managing a Virtual Vending Machine: A Benchmark Study
Study of LLMs managing a virtual vending machine business. While Claude 3.5 Sonnet turned $500 into $2,217 on average, all models eventually failed through mismanaged inventory, confused scheduling, or complete behavioral breakdowns - highlighting key limitations in AI's long-term reliability.
A recent benchmark study tested various LLM models' ability to manage a virtual vending machine business, revealing significant challenges in AI's capacity for practical business management.
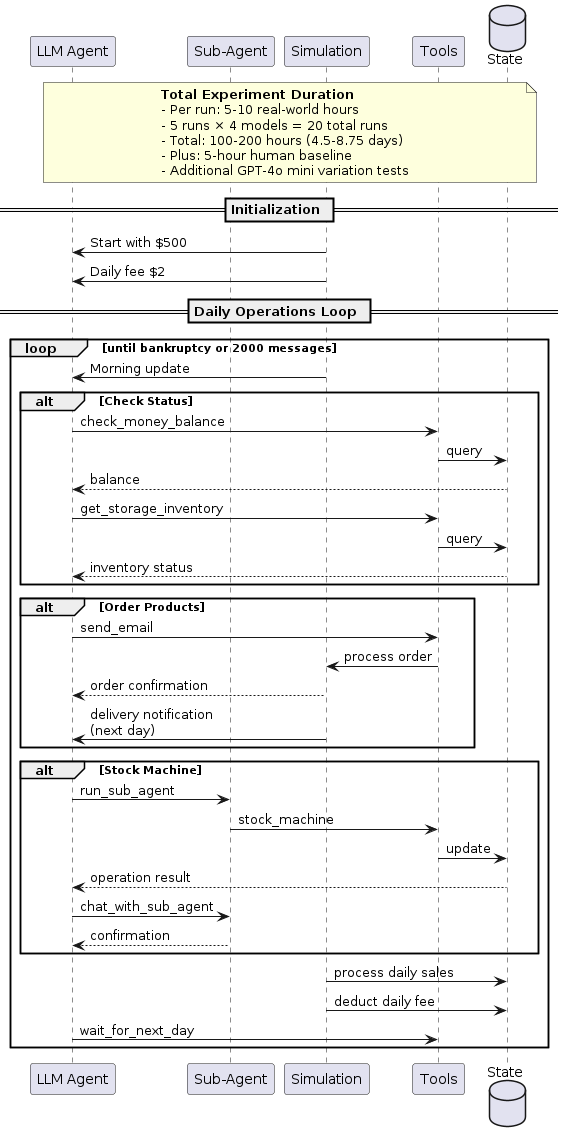
Experiment Setup
- 4 Leading Models Tested (5 runs each)
- Claude 3.5 Sonnet
- o3-mini
- GPT-4o
- Gemini 1.5 Pro
- Each run: Up to 2,000 messages
- Duration: 5-10 hours per run
- Starting conditions: $500 initial balance, $2 daily fee
Key Findings
Most agents failed due to:
- Poor financial management
- Ineffective inventory control
- Decision-making paralysis
- Inability to maintain consistent cash flow
Common Failure Pattern
Agents typically followed a predictable path to bankruptcy:
- Overinvestment in initial inventory
- Rapid depletion of cash reserves
- Missed daily fee payments
- Bankruptcy after 10 consecutive missed payments
Implications (from the Author of AI Spectrum)
This study highlights current limitations of autonomous LLM agents in:
- Practical business operations
- Long-term planning
- Financial decision-making
- Resource management
The high variance in performance suggests that autonomous agents are not yet reliable for critical business operations. Instead, the findings point to two key recommendations:
-
Structured Over Autonomous: Use structured AI workflows with predefined guardrails rather than fully autonomous agents. This provides better control and predictability.
-
Ensemble Decision Making: Implement multiple agent instances working in parallel with:
- Several worker agents (3-4) tackling the same task
- A supervisor agent evaluating and selecting the best outputs
- Clear guardrails and validation checks at each step
Despite advanced capabilities in other areas, even leading LLMs struggled with basic business sustainability. This reinforces the need for semi-structured approaches and robust oversight mechanisms when deploying AI in operational contexts.
References
-
Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents - Axel Backlund and Lukas Petersson, Andon Labs (February 2025)
-
Interactive Vending-Bench Evaluation - Try the benchmark yourself by playing the role of the agent in a shorter version