ReAct, Self-Refine, and Flow Engineering: The Three Paradigms Behind Modern AI Agents
A breakdown of the three foundational AI reasoning paradigms: ReAct, Self-Refine, and Flow Engineering, and how modern AI frameworks let you build all of them in production.
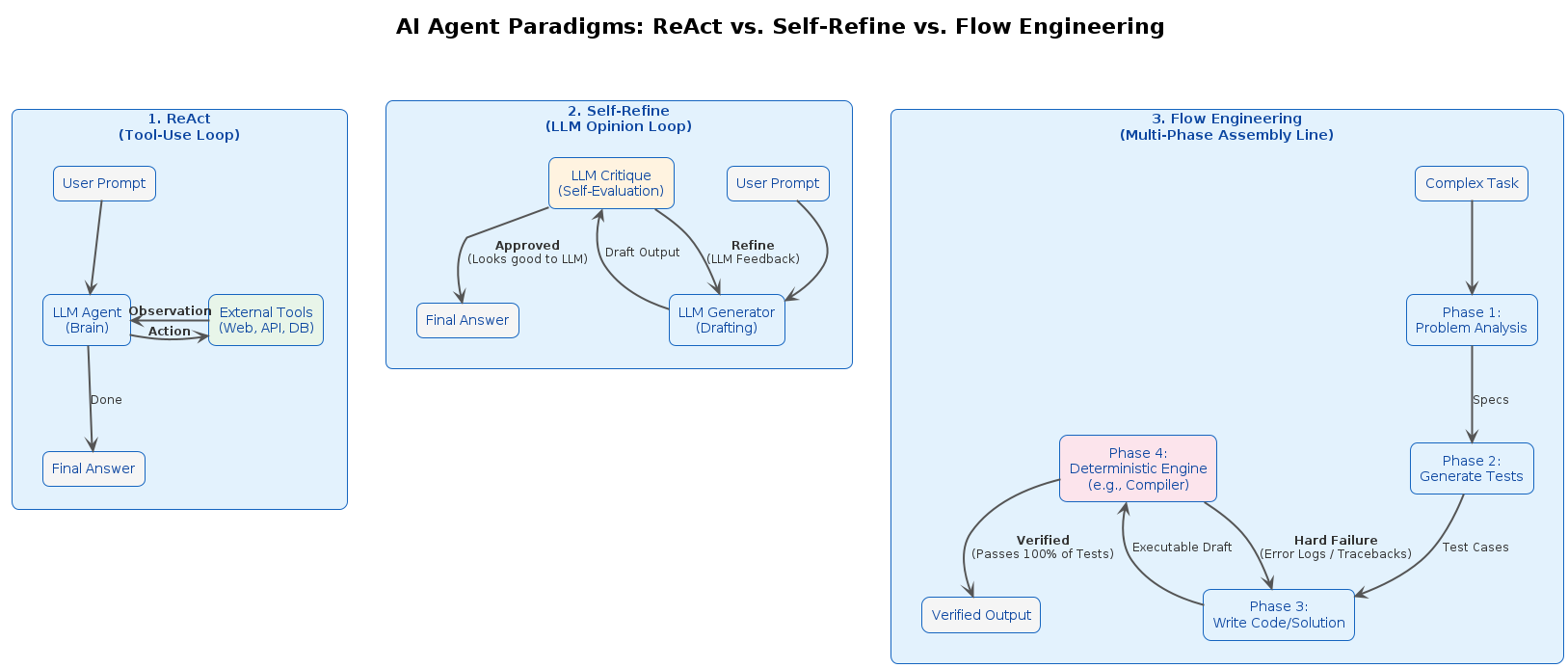
Beyond basic prompting, there are three foundational paradigms that define how AI agents reason and act: ReAct, Self-Refine, and Flow Engineering. Each solves a different problem, uses a different feedback loop, and targets a different type of task. Understanding them is the difference between blindly chaining LLM calls and deliberately engineering reliable AI systems.
The Three Paradigms at a Glance
| Paradigm | Core Idea | Feedback Source | Best Suited For |
|---|---|---|---|
| ReAct | Interleave reasoning with external actions | External environment (API calls, search) | QA, fact-checking, web agents |
| Self-Refine | Iteratively critique and improve your own output | Internal (the LLM itself) | Creative writing, code cleanup, text editing |
| Flow Engineering | Multi-stage pipeline with specialized nodes and test-driven iteration | Code execution (test pass/fail) | Competitive and complex programming |
ReAct: Reason + Act
Core concept: Synergize internal reasoning with external actions.
Think of it as an AI using a web browser. It thinks, clicks a tool, reads the result, and decides what to do next - exactly like a human would. The Action/Observation loop is the core.
ReAct forces the model to generate both a verbal reasoning trace ("thought") and a task-specific action in an interleaved loop. The model acts, receives an observation from the external environment, reasons about it, and decides the next step.
The loop:
Thought → Action → Observation → Thought → Action → ...
What makes it powerful: It grounds the model's reasoning in real-world, up-to-date observations instead of relying on internal static knowledge. This directly reduces hallucinations on knowledge-intensive tasks.
External dependency: High. ReAct requires an environment to interact with - a search API, a database, a web browser, a tool call. Without external grounding, the loop has nothing to observe.
Primary use cases: Multi-hop question answering, fact verification, web navigation, tool-use agents.
Source: ReAct: Synergizing Reasoning and Acting in Language Models
Self-Refine: Iterative Self-Improvement
Core concept: A single LLM generates output, critiques it, and refines it - with no external tools.
Think of it as a writer who is also their own editor. The model writes a draft, reviews its own work, and rewrites it until it meets its own quality bar - no outside input needed. The Critique/Refine loop is the core.
The model produces a first draft, then explicitly prompts itself to find flaws and generate actionable feedback, then uses that feedback to produce a better version. The cycle repeats until a stopping condition is met.
The loop:
Draft → Critique → Refined Draft → Critique → ...
What makes it powerful: LLMs frequently know better than their first attempt suggests. Self-Refine surfaces that latent capability by explicitly asking the model to critique and fix its own work.
External dependency: None. It runs entirely within the LLM - no tools, no training data, no APIs required.
Primary use cases: Dialogue response generation, text style transfer, code readability improvements, open-ended generation tasks where quality can be iterated.
Source: Self-Refine: Iterative Refinement with Self-Feedback
Flow Engineering
Core concept: Replace prompt engineering with a structured, multi-stage pipeline of distinct, specialized nodes.
Think of it as a full software agency. One persona plans the approach, another writes the code, and a strict testing system forces revisions until the output is programmatically verified correct. The specialized nodes are the core - each stage has one job, and the pipeline does not advance until that job passes.
AlphaCodium is the paper that introduced and named this paradigm. It operates in two phases:
Phase 1 - Pre-processing:
- Reflect on the problem statement
- Reason about public test cases
- Generate multiple candidate solutions
- Generate additional AI-authored tests
Phase 2 - Code Iterations:
- Write an initial solution
- Iteratively run and fix against public tests
- Iteratively run and fix against AI-generated tests (using "test anchors" to prevent regressions)
The loop:
Pre-process → Write → Run Tests → Fix → Run Tests → Fix → ...
What makes it powerful: It stops trying to write perfect code on the first attempt. Instead, it applies test-driven development as a feedback mechanism, using failure signals to converge on correct solutions.
External dependency: Medium. Requires a code execution environment to run tests and feed error logs back to the model.
Primary use cases: Competitive programming, complex algorithmic challenges, production code generation where correctness is non-negotiable.
Source: Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering
How They Compare
| Feature | ReAct | Self-Refine | Flow Engineering |
|---|---|---|---|
| Mental model | Human using a web browser | Writer and self-editor | Full software agency |
| Key loop | Action/Observation | Critique/Refine | Specialized nodes + test gates |
| Feedback source | External environment | The LLM itself | Code execution |
| External tools required | Yes | No | Yes (executor) |
| Loop trigger | Observation from action | Internal critique | Test pass/fail |
| Solves the problem of | Hallucinations & outdated knowledge | Sub-optimal first drafts | Syntax errors & edge-case failures |
| Complexity to implement | Medium | Low | High |
Modern AI Frameworks: The Construction Kit
No modern AI framework invented these paradigms - but they were all built to make implementing them practical. The paradigms are the blueprint; the framework is the construction kit.
Early LLM pipeline tools were too linear to handle complex, iterative, multi-step workflows. Modern frameworks solved this by modeling AI workflows as directed graphs with persistent state, making cycles (loops), conditional routing, and parallel branches first-class primitives.
1. ReAct out of the box
The most basic agent in any modern framework is a ReAct agent. Most ship a built-in helper that sets up the full Thought → Action → Observation loop with your chosen LLM and tools - it is the standard starting point for any tool-using agent.
2. Self-Refine as a natural loop
The defining feature of modern AI orchestration frameworks over simple pipeline tools is native support for cycles. A Self-Refine system is simply a graph with an edge from the "Critique Node" back to the "Generate Node," with a conditional exit when quality is sufficient. Before graph-based frameworks, implementing this reliably required significant boilerplate. In frameworks designed for it, it is a first-class pattern.
3. Flow Engineering
For complex, multi-stage pipelines, graph-based frameworks give you full control. You define a "Planner Node," a "Coder Node," and a "Tester Node," then specify exact state transitions between them. The framework handles routing - including looping back to fix code after a failing test - without the developer having to manage state manually.
What Most Production Systems Actually Use
The three paradigms above are powerful - but they are also the ceiling, not the floor. The majority of production AI systems shipping today do not use full Flow Engineering or Self-Refine loops. They rely on simpler, faster, and more predictable patterns:
Advanced RAG (Retrieval-Augmented Generation): A highly optimized, linear pipeline. The system receives a query, searches a vector database, retrieves the most relevant documents, and passes them to the LLM for a single-shot answer. No loops, no self-critique. Just a well-engineered retrieval step feeding a constrained generation step. This covers the vast majority of enterprise knowledge base, search, and Q&A applications.
Semantic Routing: A fast classifier - either a small model or an embedding-based similarity check - inspects the user's prompt and routes it to a specific, constrained prompt template or a traditional software function. The LLM never sees irrelevant instructions. Latency stays low and behavior stays predictable. Many production chatbots work this way without anyone calling them "agents."
Single-Step Tool Calling: The LLM is given a set of tools (making it look like a ReAct agent), but is heavily constrained to make one or two predictable calls before returning a final answer. There is no open-ended observation loop. The developer controls which tools exist, what they return, and when the model stops. This is ReAct with guardrails - and it is what most function-calling integrations in production actually are.
| Pattern | Loop | Complexity | Predictability | Where you see it |
|---|---|---|---|---|
| Advanced RAG | None | Low | Very High | Knowledge bases, search, Q&A |
| Semantic Routing | None | Low | Very High | Chatbots, intent classification |
| Single-Step Tool Calling | Minimal | Medium | High | CRM integrations, form automation |
| ReAct | Open | Medium | Medium | Research agents, web tasks |
| Self-Refine | Internal | Medium | Medium | Content generation, code review |
| Flow Engineering | Complex | High | Low-Medium | Coding assistants, multi-agent systems |
The lesson: reach for complexity only when simpler patterns provably fail your requirements. A well-tuned RAG pipeline beats a poorly-designed multi-agent loop on latency, cost, and debuggability every time.
The Practical Progression
These patterns form a natural progression as system requirements grow:
| Stage | Pattern | When to reach for it |
|---|---|---|
| Start here | Advanced RAG or Semantic Routing | Fixed knowledge domain, predictable intents |
| Add tools | Single-Step Tool Calling | Need one or two external lookups |
| Add autonomy | ReAct | Tasks require open-ended tool use |
| Add quality gates | ReAct + Self-Refine | Output correctness is critical |
| Add orchestration | Full Flow Engineering | Multi-step, multi-agent, verifiable pipelines |
Start with the simplest pattern that solves the problem. Most applications never leave the first two rows. When reliability requirements push you toward more autonomy, add one layer of complexity at a time - and always ask whether a constrained version of the next pattern is sufficient before building the full one.
The paradigms are the theory. The simpler patterns are where most production systems live. Modern AI frameworks are the tools that let you move between all of them without rewriting your architecture.