SCOPE: How I Write Software Specs in the Era of AI Agents
PRDs and SRDs were built for humans. In the age of AI agents, I replaced them with SCOPE, a lightweight spec format designed around the exact ways LLMs fail.
Before AI agents, I wrote software by producing a PRD and an SRD, detailed and structured documents that a human developer could sit down with, ask questions about, and reason through. That worked well when the primary consumer of the spec was a person.
It stopped working the moment the primary consumer became an LLM.
The Problem with Human-Readable Specs for AI
Traditional PRDs and SRDs are full of institutional knowledge that humans carry implicitly. "Don't break the checkout flow" means something to an engineer who has been on the team for six months. To an AI agent, it means nothing without context.
LLMs also fail in predictable, specific ways when given underspecified tasks:
- They take the path of least resistance, introducing tech debt
- They invent new components instead of reusing existing ones
- They hallucinate APIs, package names, and database schemas
- They write for the happy path and skip edge cases entirely
- They violate compliance rules they were never told about
The solution is not to write longer specs. It is to write specs structured around how LLMs actually process information.
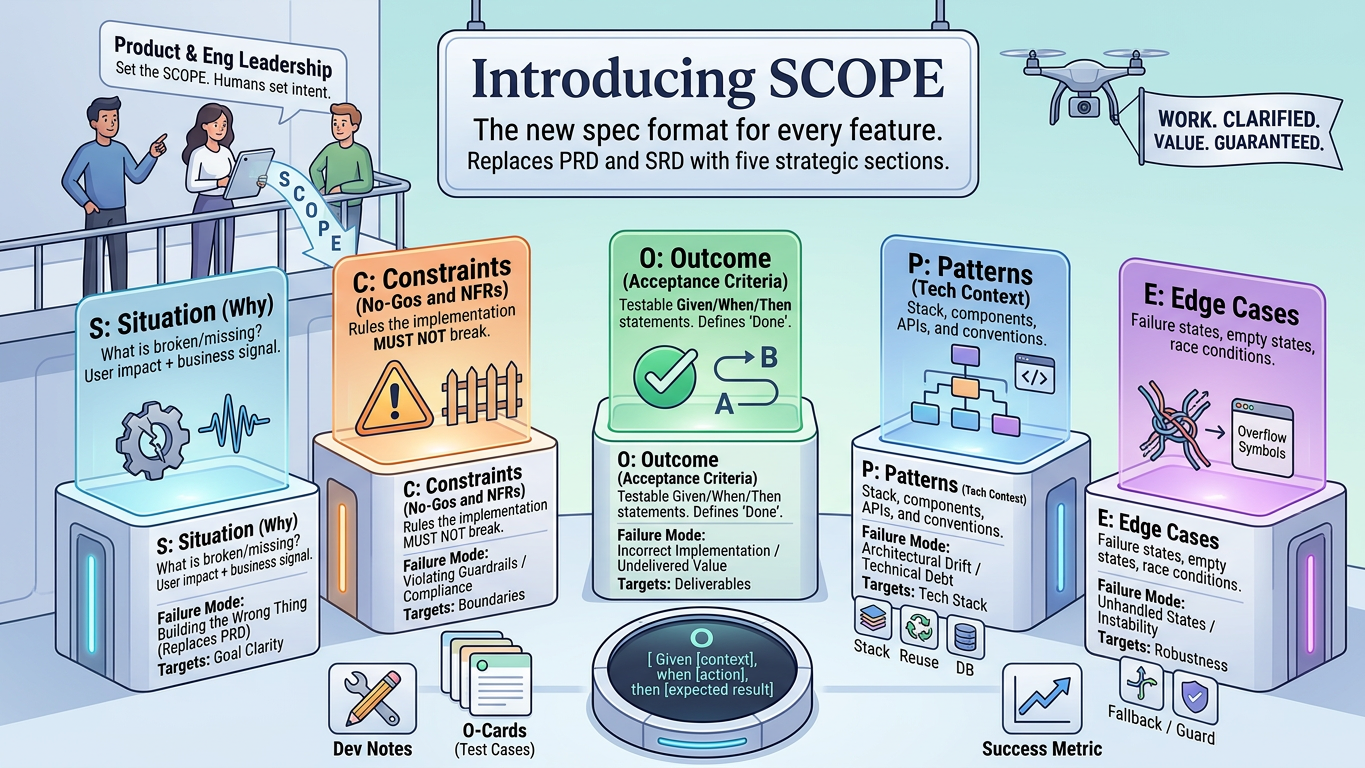
Introducing SCOPE
SCOPE is the spec format I now use for every feature. It replaces the PRD and SRD with five sections, each one targeting a specific failure mode in AI-assisted development.
[Feature / Epic Name]
S: Situation (Why)
What is broken or missing? Include user impact and business signal (1-3 sentences).
C: Constraints (No-Gos and NFRs)
Rules the implementation MUST NOT break.
[Rule]: [Reason]
O: Outcome (Acceptance Criteria)
Testable Given/When/Then statements defining "done".
[ ] Given [context], when [action], then [expected result]
P: Patterns (Tech Context)
Stack, components, APIs, and conventions to follow.
Stack/API: ...
Reuse: ...
DB: ...
E: Edge Cases
Failure states, empty states, race conditions, and boundary conditions.
What if [X fails]? → [Fallback / Guard]
Dev Notes & Success Metric
Dev Notes: [Implementation decisions chosen]
Success Metric: [One signal proving production success]
Here is a real example for a checkout error recovery feature:
[Checkout Card Error Recovery]
S: Situation
Users see a generic "Error" on card failure and abandon checkout.
Losing ~12% of attempts to recoverable errors (expired card, insufficient funds).
C: Constraints
No multi-step email flows (1 max) | No raw card data in logs (PCI compliance)
Preserve all user inputs on retry | No changes to the Stripe webhook handler
O: Outcome
[ ] Given an expired card, when submitted, then show inline "Card expired. Please update your card" (no modal)
[ ] Given a recoverable error, when triggered, then send one recovery email within 60 seconds
[ ] Given a user pays after email is queued, when payment succeeds, then cancel the queued job
P: Patterns
Stack: Next.js 14, Stripe SDK v12, Stripe error codes (card_declined, expired_card)
Reuse: <ErrorBanner> at /components/ui/ErrorBanner.tsx
DB: add recovery_sent boolean to checkout_sessions table
E: Edge Cases
Job fires twice → recovery_sent flag prevents double-send
User updates card mid-flow → optimistic lock on checkout session
Stripe webhook delayed → idempotency key on recovery job
Dev Notes: Use Stripe's decline_code for granular inline messaging
Success Metric: Checkout abandon rate drops below 5% within 7 days
Why Each Section Targets a Specific LLM Failure Mode
S: Situation (Context injection)
LLMs make significantly better micro-decisions when they understand intent. Knowing that 12% of checkout attempts are abandoned to recoverable errors changes every implementation choice the model makes, from error copy to retry logic. Without this context, it optimizes for passing tests, not for solving the actual problem.
C: Constraints (Negative prompting)
This is arguably the most important section. LLMs default to the simplest possible implementation. Without explicit constraints, they will introduce new abstractions, ignore compliance requirements, and happily break adjacent systems. Constraints function as negative prompts: they define the boundary of acceptable solutions before any code is written.
O: Outcome (BDD-native acceptance criteria)
The Given/When/Then format is not just borrowed from Behavior-Driven Development for familiarity. It translates directly into test cases. An AI agent can read these statements and write the test suite before touching the implementation. This enables genuine TDD: the outcome section is the spec, and the tests are the contract.
P: Patterns (Anti-hallucination layer)
Left to their own devices, AI agents will invent new components, pull in unnecessary dependencies, or hallucinate API signatures they have never seen. The Patterns section prevents this by pointing the agent directly at what already exists: the component file path, the SDK version, the specific database column to add. This is the part of the spec that enforces code reuse and keeps repositories coherent across many AI-generated features.
E: Edge Cases (Forcing robustness)
AI agents optimize for the happy path. They will write the success branch cleanly and skip the failure handling unless explicitly directed otherwise. Listing edge cases forces the agent to reason about race conditions, duplicate triggers, and boundary states that it would otherwise leave as unhandled exceptions.
The Multi-Agent Pipeline
The SCOPE spec feeds a five-stage pipeline:
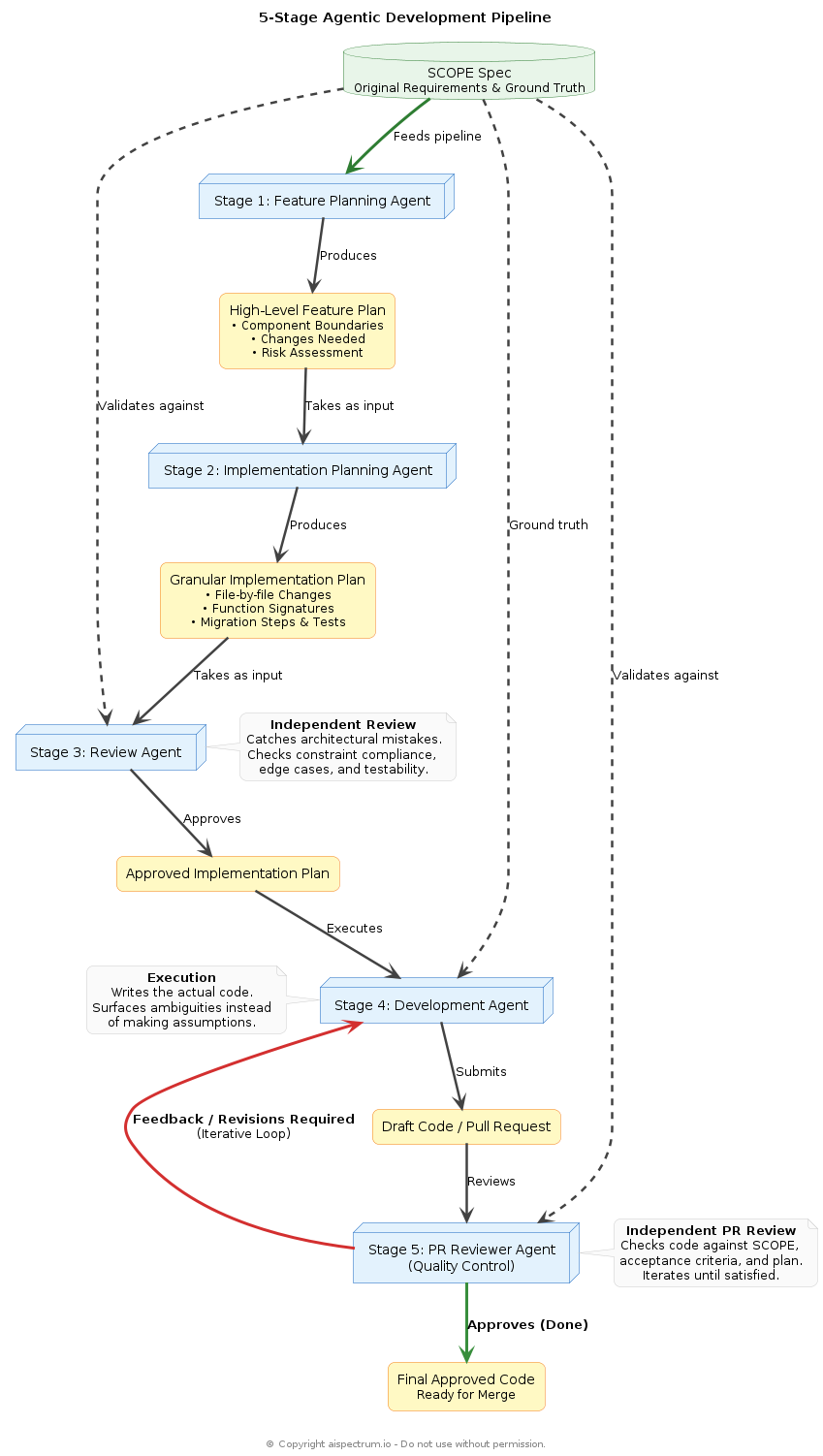
Stage 1: Feature Planning Agent Takes the SCOPE spec and produces a high-level feature plan: what changes, what the component boundaries are, what risks exist.
Stage 2: Implementation Planning Agent Takes the feature plan and produces a granular implementation plan: file-by-file changes, function signatures, migration steps, test cases to write.
Stage 3: Review Agent An independent agent reviews the implementation plan against the original SCOPE spec. It checks constraint compliance, edge case coverage, and whether the acceptance criteria are actually testable. This catches architectural mistakes before a single line is written.
Stage 4: Development Agent Executes the implementation plan with the SCOPE spec as its ground truth. If a decision arises that the spec does not cover, it surfaces the ambiguity rather than making an assumption.
Stage 5: PR Reviewer Agent (Quality Control) An independent agent reviews the output of the Development Agent as if conducting a pull request review. It checks the code against the SCOPE spec, the acceptance criteria, and the implementation plan. If it finds gaps, violations, or incomplete edge case handling, it sends the work back to the Development Agent with specific feedback. This review-and-revise loop runs across as many iterations as needed until the PR Reviewer is satisfied the output meets the original spec. Only then is the work considered done.
This pipeline mirrors the Plan-and-Solve and Actor-Critic architectures that underpin frameworks like Microsoft AutoGen and ChatDev. The key insight is the same: forcing a planning pass before execution, and a review pass before coding, eliminates the largest class of AI coding failures, specifically the rabbit holes that produce a lot of code that does not solve the right problem.
The SDLC as an Event-Sourced Ledger
If you adopt this framework completely, a natural question arises: If every feature and bug fix is driven by a SCOPE file, does the software's documentation just become a chronological chain of these files?
The short answer is yes, and that is actually a massive advantage.
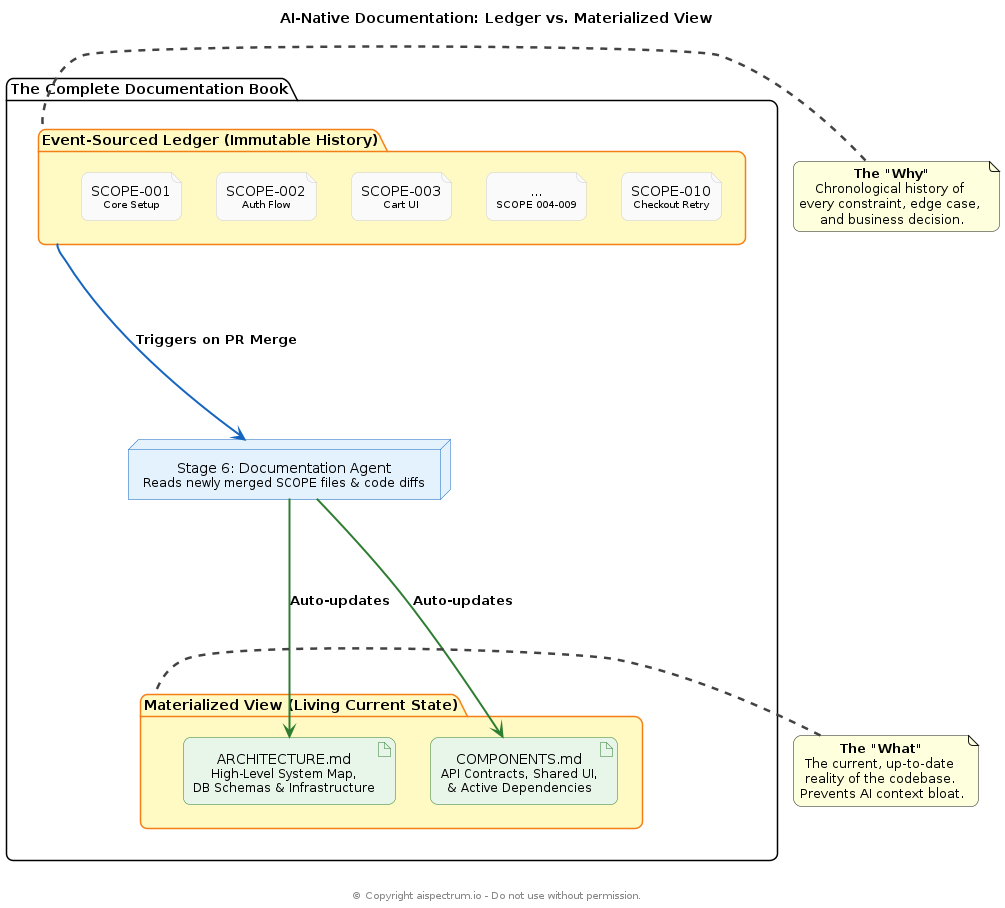
In database architecture, there is a concept called Event Sourcing. Instead of storing the current state of a record, you store an immutable log of every event that changed it. Chaining SCOPE files does exactly this for your SDLC. Traditional documentation tells you what the system does today. A repository of historical SCOPE files tells you exactly why it was built that way. If a developer (or an AI agent) wonders why a bizarre retry logic exists in the checkout flow, they don't have to guess. They can pull up the exact SCOPE file from six months ago and read the Situation and Constraints from that exact moment in time.
However, an event-sourced ledger is not enough on its own. If a core component has been modified by 15 different SCOPE files over two years, forcing a new AI agent to read all 15 files to understand how the component works today is highly inefficient and consumes massive context windows.
If the SCOPE files are the event ledger, your documentation still needs a Materialized View, a living document that represents the system's current state.
In an AI-native pipeline, this doesn't mean going back to writing manual documentation. Instead, it introduces one final step to the multi-agent pipeline:
Stage 6: The Documentation Agent
Once the PR Reviewer Agent (Stage 5) approves the code and it merges into the main branch, a Documentation Agent wakes up. It takes the original SCOPE file, looks at the final diff, and automatically updates the repository's master ARCHITECTURE.md and component-level readmes.
The SCOPE files remain untouched as the perfect historical record of intent. The living documentation stays perfectly up-to-date as the map of the current territory. Together, they form the ultimate documentation book for the Software 3.0 era.
Where This Sits in the Industry
There is no single "industry standard" for Software 3.0 spec writing yet. The space is genuinely unsettled.
In the Software 2.0 world, the standards are well-established: Agile user stories, BDD with Gherkin syntax, TDD with test-first development. These work for human developers. The Outcome section of SCOPE borrows directly from BDD, and deliberately so. Given/When/Then is one of the few spec primitives that bridges human product thinking and machine-executable criteria cleanly.
In the AI-native world, most teams are improvising. Some write unstructured rules.md files and hope the agent respects them. Others write full PRDs and feed them wholesale into a context window. A growing number are building what are essentially structured prompting templates, which is exactly what SCOPE is, formalized into a repeatable workflow.
Frameworks like Aider, Cursor, and Devin are converging on the same realization: the spec quality determines the output quality more than the model capability does. SCOPE is an attempt to make spec quality systematic rather than incidental.
One Enhancement Worth Adding
The one gap in the original SCOPE format is explicit data contracts between frontend and backend. When two AI agents are working on different layers of the same feature, ambiguous data shapes produce integration bugs that are painful to debug.
Adding a schema to the Patterns section eliminates this:
P: Patterns
...
Contract: { error_code: string; recoverable: boolean; retry_url: string | null }
One type definition, shared as ground truth with both agents, eliminates an entire class of integration failures.
What Changes About Engineering
SCOPE is not just a spec format. It reflects a broader shift in what the engineering job actually is.
The intelligence required to write, debug, and refactor code is increasingly available in the model. What is not in the model is institutional knowledge: what constraints apply, which components exist, what "done" looks like for this specific product in this specific codebase.
The engineer's job in Software 3.0 is to capture that institutional knowledge in a form that an AI agent can act on reliably. SCOPE is that form. Tight, unambiguous, structured around the exact ways LLMs fail, and built so the agent can move fast without the spec author having to be in the loop for every decision.
Start Writing Your First SCOPE Spec
Copy the template below and fill in the blanks:
Write a spec for: [Insert feature/fix idea]
Situation (1-2 sentences on why/impact):
Constraints (Strict rules and no-gos):
Outcomes (Given/When/Then acceptance criteria):
Patterns (Stack, files to reuse, DB changes):
Edge Cases (Failure states and fallbacks):
Option A: Raw LLM Prompt
Paste this directly into any LLM:
Please generate a SCOPE specification for the following feature/fix:
[INSERT FEATURE/FIX DESCRIPTION HERE]
Analyze the request and output STRICTLY in the following format. Do not include any conversational filler before or after the spec.
# [Feature / Epic Name]
**S: Situation (Why)**
[Write 1-3 sentences explaining what is broken or missing, including user impact and business signal]
**C: Constraints (No-Gos and NFRs)**
- [Rule]: [Reason]
- [Rule]: [Reason]
**O: Outcome (Acceptance Criteria)**
- [ ] Given [context], when [action], then [expected result]
- [ ] Given [context], when [action], then [expected result]
**P: Patterns (Tech Context)**
- Stack/API: [Identify stack, APIs, or SDKs needed]
- Reuse: [Identify existing components/files that should be reused]
- DB: [Identify necessary database/schema changes, or write "None"]
**E: Edge Cases**
- What if [X fails]? -> [Fallback / Guard]
- What if [Y happens]? -> [Fallback / Guard]
**Dev Notes & Success Metric**
- Dev Notes: [Key implementation decisions chosen]
- Success Metric: [One specific signal proving production success]
Option B: Claude Code Ecosystem
If you are working inside Claude Code, use the built-in spec-writer agent skill. It wraps the SCOPE format natively and integrates with your project context.
Option C: SuperClaude Framework
If you use the SuperClaude meta-programming framework, you can generate a SCOPE spec with:
/sc:design => sc:brainstorm
or open the full spec panel with:
/sc:spec-panel
This framework emerged from working directly with AI coding agents on production features. The multi-agent pipeline references architectures described in the Microsoft AutoGen research and the ChatDev paper.